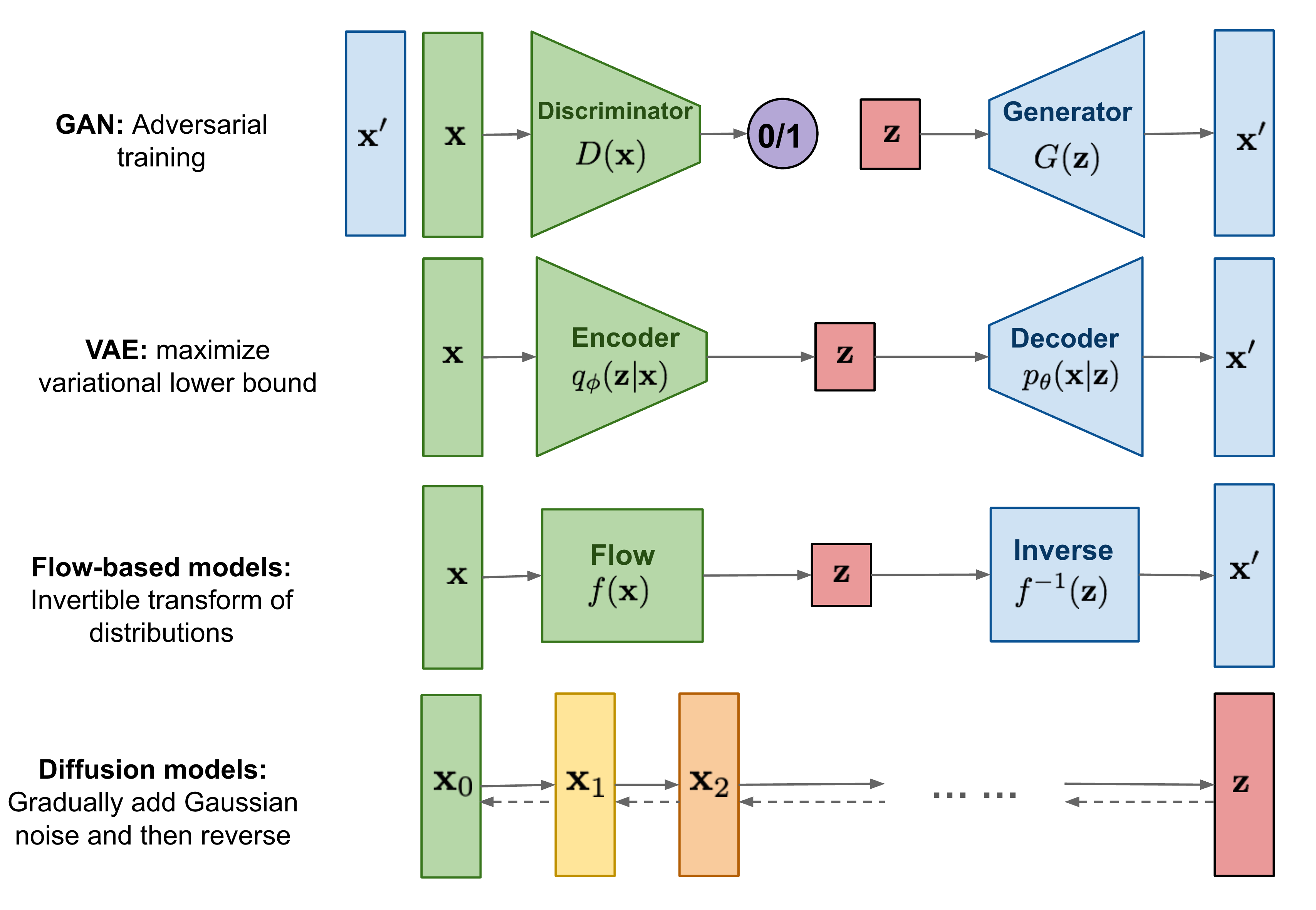
8 Image Generation
Генеративные модели в компьютерном зрении (генеративно-состязательные нейронные сети). Принцип работы генератора и дискриминатора.¶
Формально задача порождающих моделей, с точки зрения максимизации правдоподобия, выглядит следующим образом: для набора данных \(D = {x_i}^N){i=1}\) максимизировать \(\Pi^N_{i=1}(x_i,\theta)\).
Также мы можем думать о задаче максимизации правдоподобия, как о задаче минимизации KL дивергенции (позволяет померить расстояния между распределениями, чем оно меньше, тем лучше генерируем):
Таким образом мы хотим имея случайный вектор и класс \(Y\) сгенерировать синтетический пример \(X\) и найти условное распределение \(P (X | Y)\)
Свойства, которые нужно достичь:
-
Точность (Fidelity) -- отвечает за качество генерируемых примеров, их реалистичность;
-
Разнообразие (Diversity) -- Генератор не должен порождать одно и тоже.
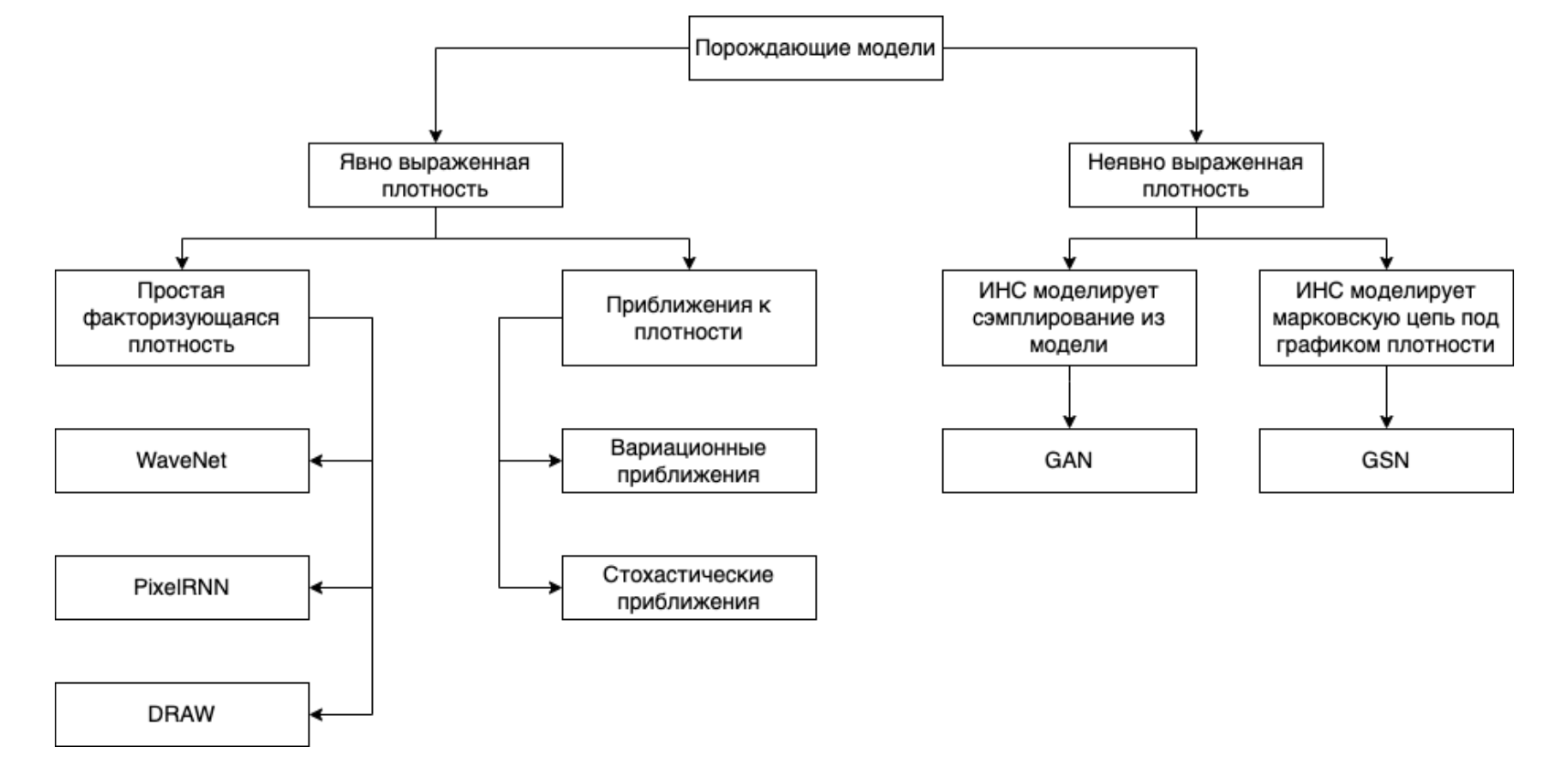 |
|---|
| Таксономия(классификация) порождающих моделей |
GAN¶
GAN - одна из наиболее эффективных архитектур для создания реалистичныйх данных.
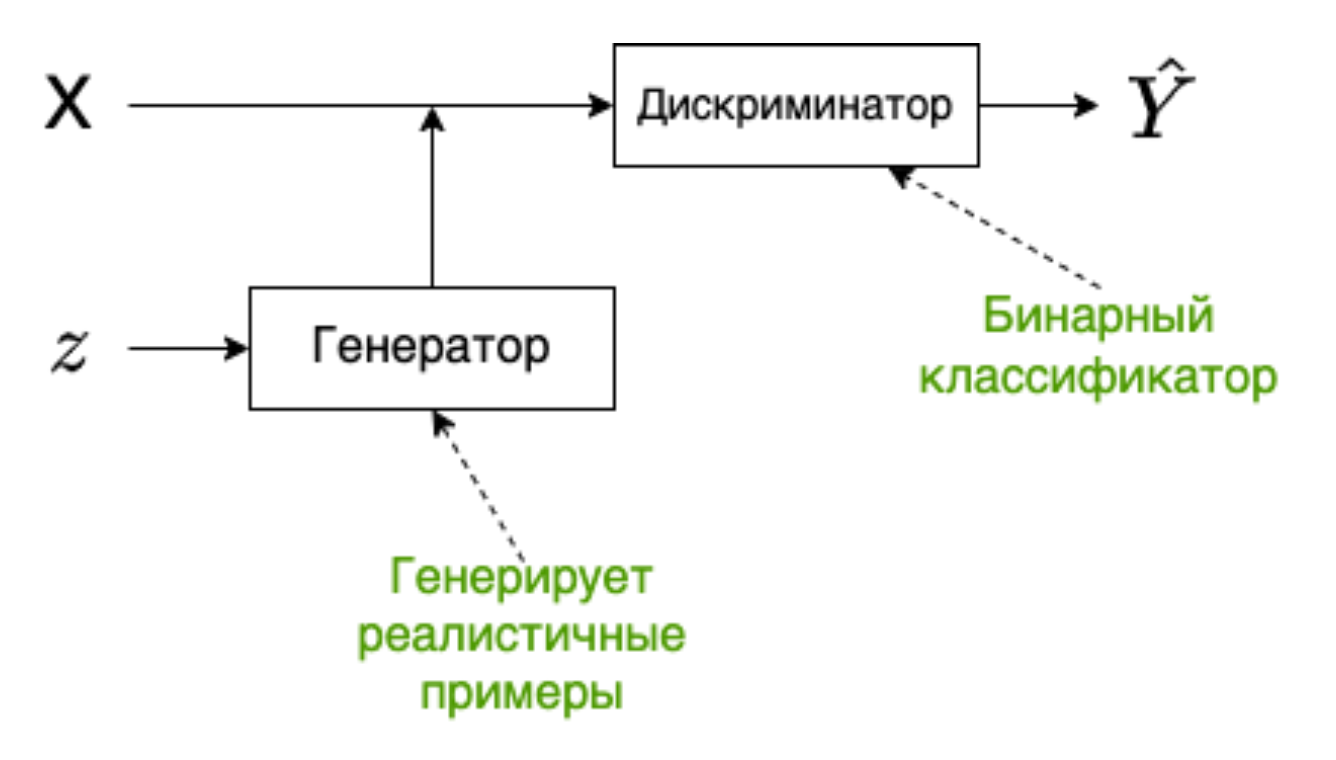 |
|---|
| Архитектура GAN |
Состоит из двух сетей: генератора и дискриминатора.
Генератор -- порождает объекты в пространстве синтетических данных. Он пытается «обмануть» дискриминатор, сделать так, что дискриминатор не может различать распределение реальных данных и распределение синтетических, которое порождает генератор.
Дискриминатор -- классификатор, который учится отличать порожденные объекты от примеров из обучающей выборки.
Обучение генератора и дискриминатора¶
Процесс обучения GAN выглядит следующим образом: создаем случайный вектор \(z\), подаем его на вход генератору, генератор порождает синтетический пример \(\hat{X}\), далее \(\hat{X}\) и пример из реальных данных \(X\) подаются в дискриминатор, который выдает вероятность того что, синтетический пример является действительно синтетическим или нет. После чего вычисляется значение функции потерь и выполняется обратное распространение ошибки только для дискриминатора, с корректировкой весов дискриминатора.
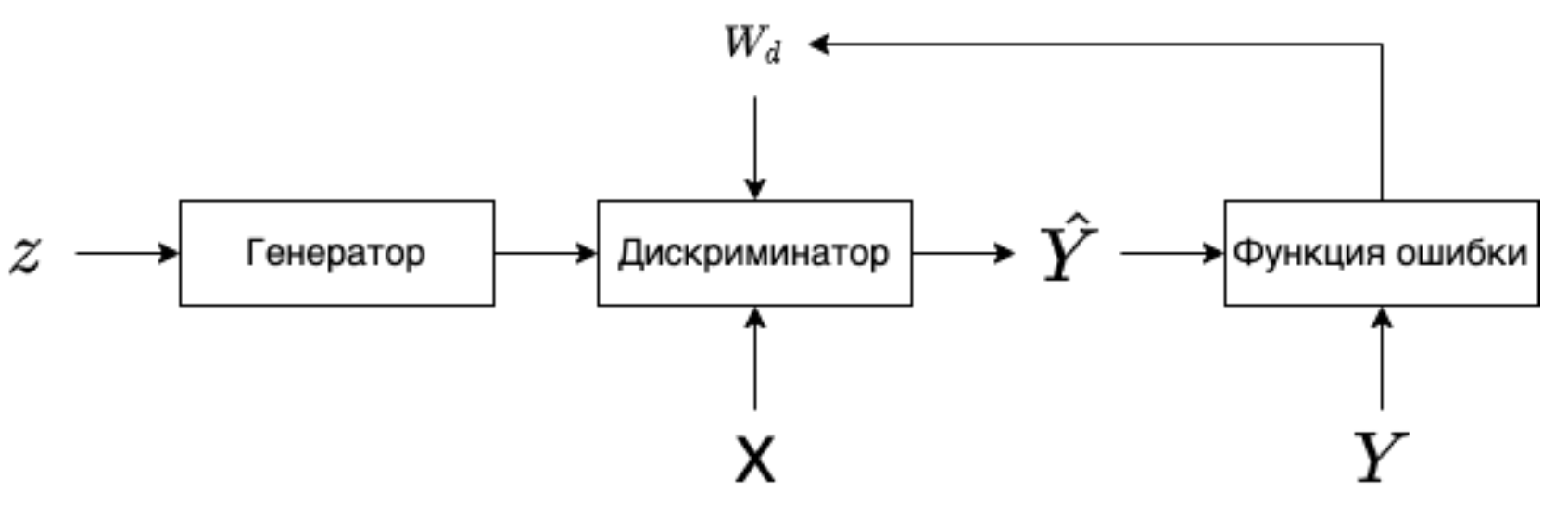 |
|---|
| Обучение дискриминатора |
Далее выполняется следующий шаг обучения, только на этом этапе в дискриминатор мы подаем \(\hat{X}\). В функции ошибки мы рассматриваем только метки, которые совпали с реальными, после чего выполняем обратное распространение ошибки для генератора, дискриминатор в этом процессе не участвует. Затем корректируем веса генератора.
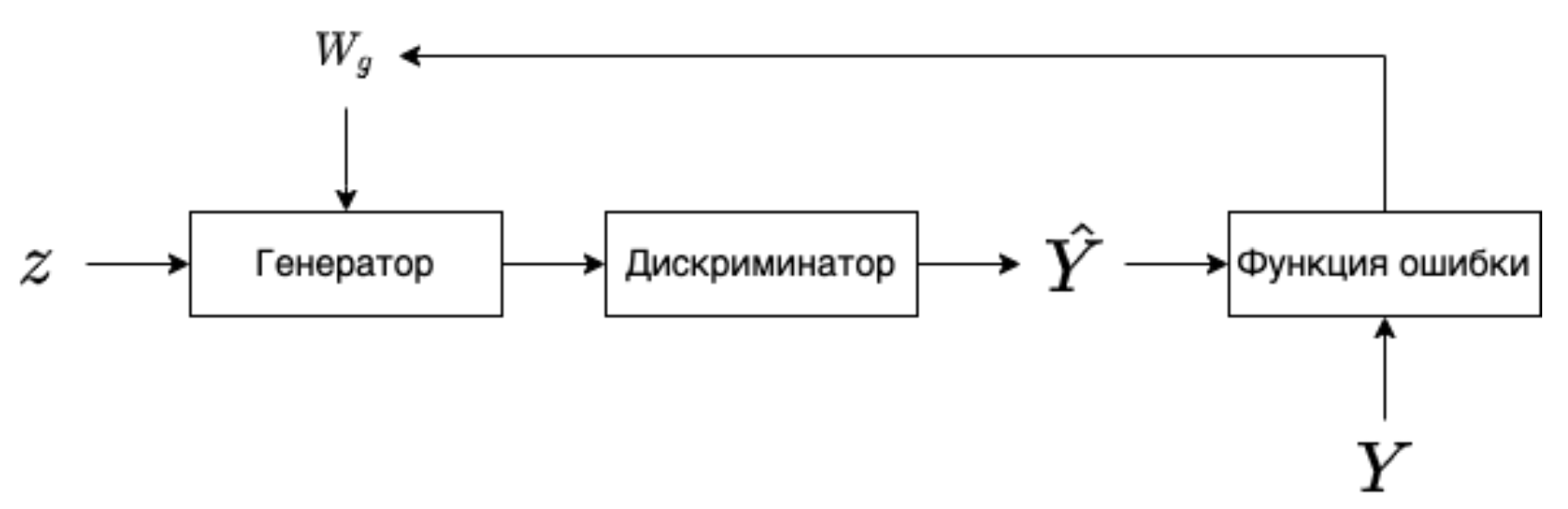 |
|---|
| Обучение генератора |
В процессе тренировки качество генератора и дискриминатора должно оставаться сопоставимым, иначе если дискриминатор распознает синтетические данные со \(100\%\) вероятностью, генератор перестанет учиться.
Недостатки GAN
Главным недостатком GANs является попадание модели в состояние mode collapse. (например дискриминатор быстрее обучается (ему нужно просто провести гиперплоскость между двумя распределениями), тогда генератор больше не сможет обучаться, нужно искать баланс, чтобы дискриминатор помогал обучаться генератору)
Следствие попадания в состояние mode collapse: модель постоянно генерирует пример или примеры одного и того же класса или нескольких классов, хотя обучалась она на примерах, размеченных для большего количества классов.
Это проблема разнообразия (diversity). Такое происходит когда генератор застревает в локальном минимуме и объединяет несколько мод (mode - пик в распределении) в одну, после чего генерирует только эту моду.
Этот недостаток был связан в первую очередь с тем, что повсеместно применяли в качестве функции ошибки бинарную перекрестную энтропию
Лосс и метрики¶
Бинарная перекрестная энтропия (BCE) - часто использовали, возникает проблема с разнообразием при обучении, так как дискриминатор менее глубокий, обычно, и учится быстрее. BCE на некоторых участках не имеет наклона, что приводит к проблеме исчезающего градиента.
Расстояние Вассерштейна - нужно, чтобы сравнивать не метки классов, а распределения данных.
Earth Movers Distance (EMD) - измеряет расстояние между двумя распределениями и оценивает усилия, необходимые для того чтобы генерируемое распределение сделать очень похожим на реальное.
Аппроксимацией EMD является расстояние Вассерштейна или W-loss.
Генератор пытается минимизировать расстояние, а critic максимизировать. Важное требование к функции critic, она должна быть 1-L непрерывной по Липшицу. Это означает что норма для градиента в любой точке не должна быть больше единицы \(||f(x)||_2 \leq 1\)
Расстояние Фреше или Frechet inception distance (FID), одна из основных метрик оценки качества для GAN. Изначально эта метрика применялась для измерения расстояния между двумя кривыми, но в последствии стало понятно, что с помощью данной метрики можно сравнивать распределения.
Общая формула:
Одномерный случай:
Базовый подход для рассчета FID, на примере генерации изображений, содержит следующие шаги:
Input: Функция для генерации эмбедингов \(f: \Omega_X \rightarrow \mathbb{R}^n\); Два датасета: с изображениями из выборки \(S \subset \Omega_X\) и сгенерированные \(\hat{S}\)
Algorithm:
- Посчитать эмбединги для данных двух наборов данных \(f(S), f(\hat{S})\)
- Найти нормальные распределения \(\mathcal{N}(\mu, \Sigma)\) и \(\mathcal{N}(\hat{\mu}, \hat{\Sigma})\) для полученных \(f(S), f(\hat{S})\).
- Посчитать \(d(\mathcal{N}(\mu, \sigma), \mathcal{N}(\hat{\mu}, \hat{\sigma}))\)
Inception score Идея состоит в том что мы берем предобученный классификатор Inceptionv3, подаем на вход сгенерированный пример и смотрим распределение вероятностей по классам, один из классов должен иметь макс значение, тогда у нас соблюдается точность (fidelity), а тот факт что у других классов вероятность > 0 говорит о разнообразии (diversity).
Недостатки:
Не замечает проблем с разнообразием(diversity) -- к примеру модель будет генерировать одно и тоже изображение для каждого класса, IS покажет хорошую оценку, но в идеале GAN должен уметь генерировать несколько разных изображений для одного класса. Это явно говорит о mode collapse.
Учитывает только сгенерированные сэмплы -- не выполняет сравнение между реальными и сгенерированными сэмплами.
Итог:
-
FID измеряет расстояние между распределениями изображений в пространстве признаков, вычисленных с помощью нейронной сети Inception. Чем меньше FID, тем более схожи генерируемые изображения с реальными.
-
IS оценивает качество генерируемых изображений, используя контрастность и энтропию классификации, выполненной с помощью нейронной сети Inception. Чем выше IS, тем более разнообразны и качественны генерируемые изображения.
Autoencoder. Variational autoencoder. Примеры прикладных задач. Концепция сжатия информации. KL-дивергенция. Трюк с репараметризацией.¶
Autoencoder — это искусственная нейронная сеть, используемая для обучения без учителя в глубоком обучении, т.е. где целевые выходные данные совпадают с входными данными. Состоит из двух частей: encoder (кодировщик), который переводит входные данные в более низкоразмерное представление, и decoder (декодировщик), который восстанавливает данные из этого низкоразмерного представления.
Архитектура обычного autoencoder выглядит так:
- Encoder: \(h = f(x)\)
- Decoder: \(x' = g(h)\)
где \(x\) - входные данные, \(h\) - скрытое представление, \(x'\) - восстановленные данные. Функции \(f(·)\) и \(g(·)\) - это нейронные сети.
Цель - минимизировать ошибку восстановления, т.е. различия между входными и восстановленными данными:
где \(L(·)\) это функция потерь, например, среднеквадратичная ошибка.
Variational Autoencoder (VAE) - это расширение autoencoder, которое добавляет статистический слой в процесс кодирования и декодирования, позволяя генерировать новые данные, похожие на обучающую выборку.
Вместо того, чтобы кодировать входное значение \(x\) в фиксированное значение \(h\), VAE кодирует \(x\) в параметры распределения, обычно в среднее и дисперсию Гауссова распределения:
Затем значение \(h\) генерируется путем выборки из этого распределения. Это делается с использованием трюка с репараметризацией для обеспечения дифференцируемости.
Цель VAE - минимизировать ошибку восстановления, как и в случае с autoencoder, но также минимизировать разницу между распределением кодированных данных и заданным априорным распределением (обычно стандартное нормальное распределение). Это достигается путем минимизации следующей функции потерь:
где \(KL(·||·)\) это KL-дивергенция, которая измеряет, насколько одно распределение отличается от другого.
KL-дивергенция, или относительная энтропия, - это мера, насколько одно вероятностное распределение отличается от другого. Для двух дискретных распределений \(P\) и \(Q\) она определяется следующим образом:
Трюк с репараметризацией Трюк с репараметризацией используется в VAE для того, чтобы сделать процесс выборки из распределения дифференцируемым. Вместо того, чтобы прямо выбирать значение \(h\) из распределения, определенного параметрами \(\mu\) и \(\sigma\), мы выбираем значение \(\epsilon\) из стандартного нормального распределения и вычисляем:
Таким образом, градиенты могут свободно проходить через этот процесс выборки.
Примеры прикладных задач¶
- Снижение размерности: Autoencoder может быть использован для снижения размерности данных, что может быть полезно для визуализации или предварительной обработки данных перед использованием в других алгоритмах машинного обучения.
- Удаление шума: Autoencoder может быть обучен игнорировать шум в данных, т.е. когда целью является восстановление исходных, чистых данных из зашумленных входных данных.
- Генерация новых данных: VAE, благодаря своему статистическому подходу, может генерировать новые данные, похожие на те, на которых он был обучен. Это делает его полезным для таких задач, как генерация новых изображений или текста.
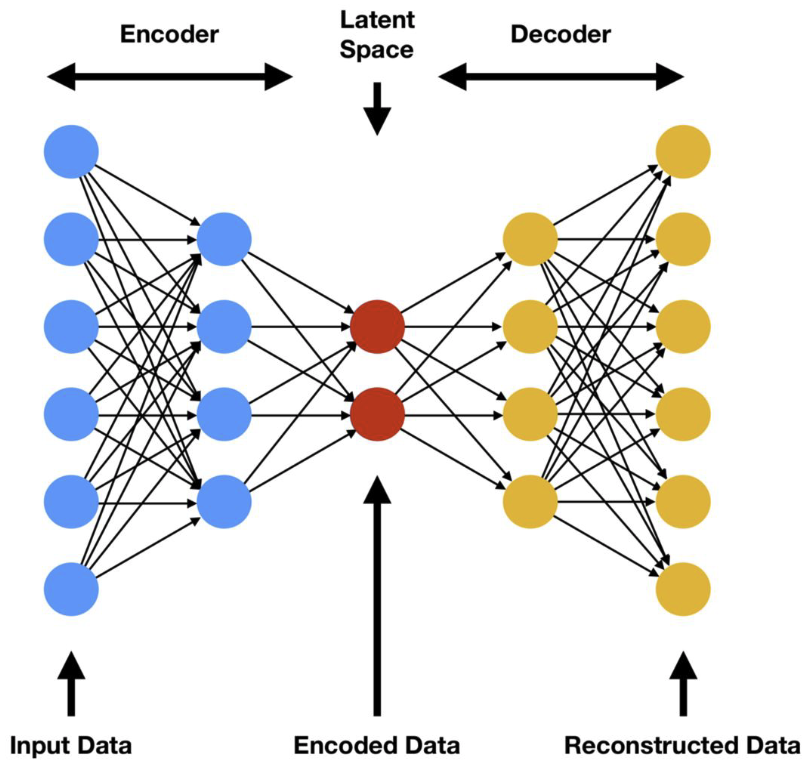 |
|---|
| Архитектура AutoEncoder |
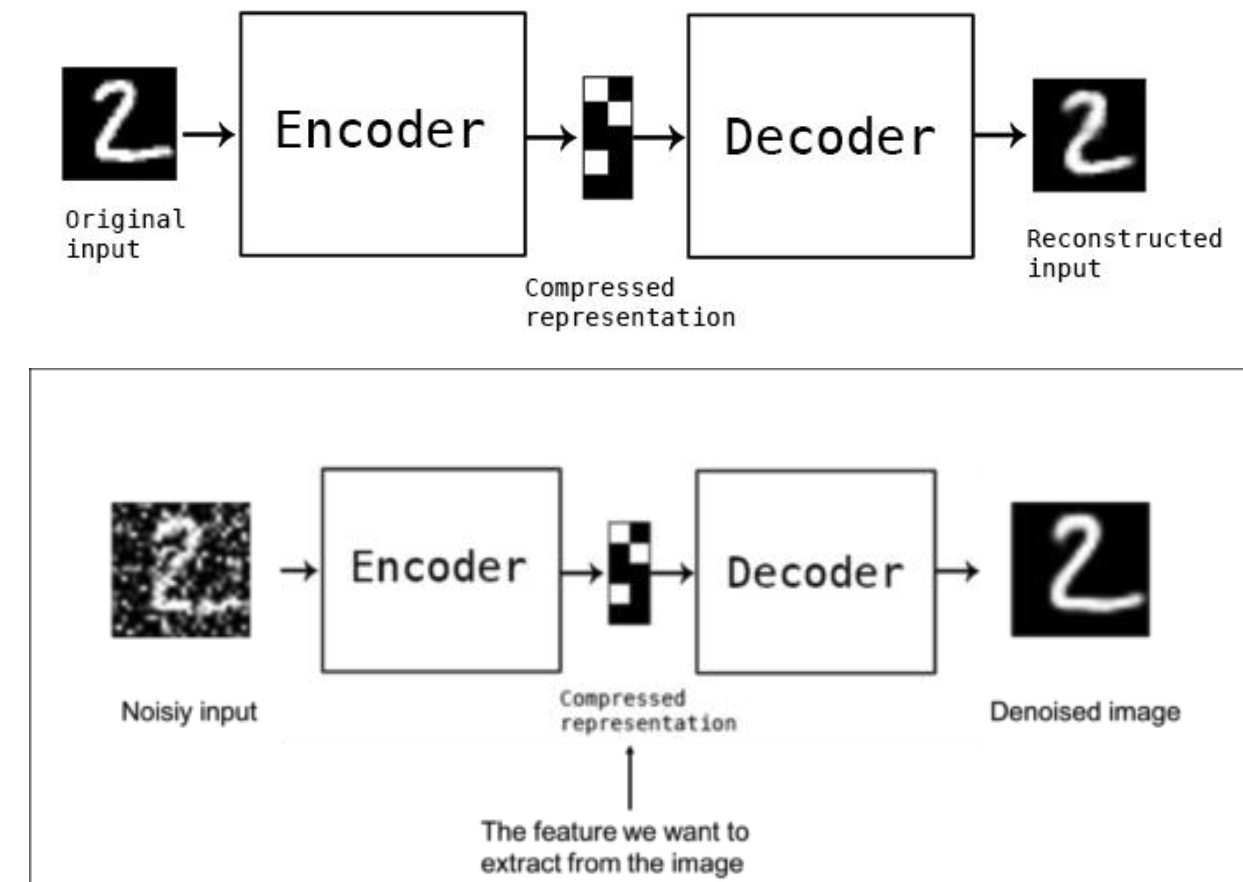 |
|---|
| Denoising AutoEncoder. Автоэнкодер можно применять как средство для понижения шума. |
Диффузионные модели. Прямой проход. Обратный проход.¶
Диффузионные модели в машинного обучения - это класс моделей, которые генерируют новые данные путем итеративного процесса, напоминающего случайное блуждание или диффузию.
Прямой проход (Forward Pass) - в прямом проходе, мы итеративно добавляем шум к исходным данным. Этот процесс можно описать следующими формулами. Пусть \(x_0\) - это наши исходные данные, тогда \(x_t\) - это данные на шаге \(t\).
здесь \(\beta_t\) - это шум на шаге \(t\), а \(\varepsilon_t\) - это выборка из стандартного нормального распределения. Следует отметить, что \(\beta_t\) обычно выбирается так, чтобы увеличивать количество добавляемого шума с течением времени.
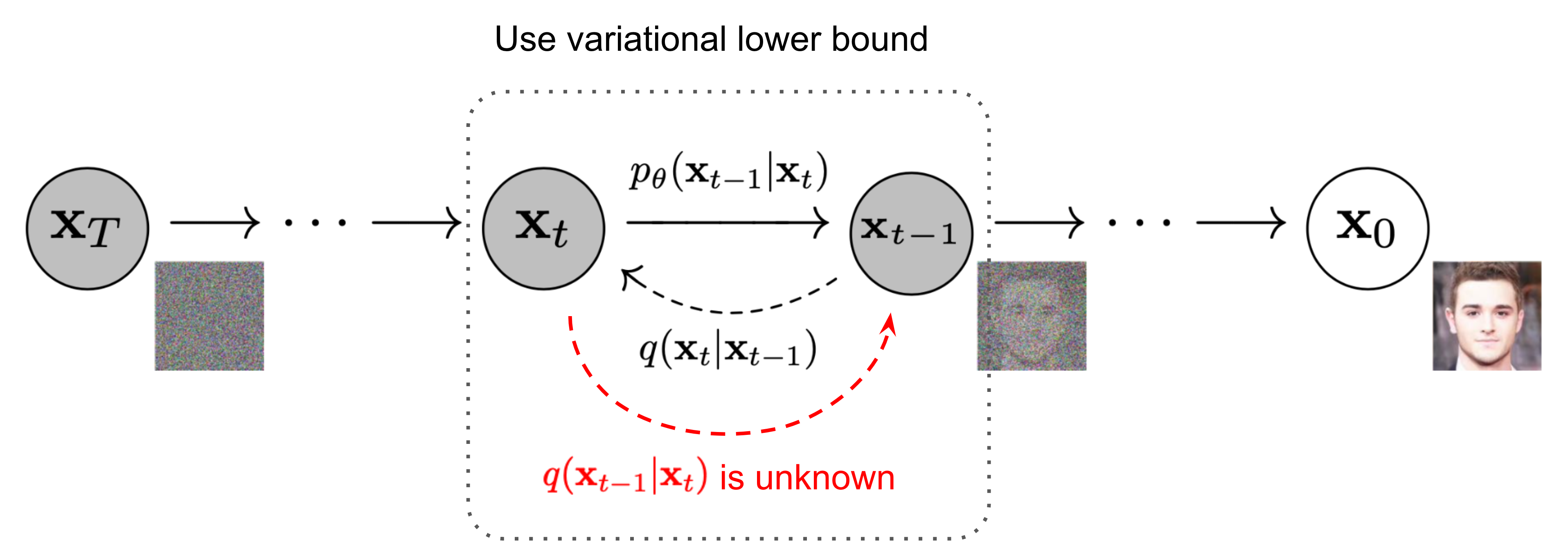
Обратный проход (Backward Pass) - это процесс восстановления исходных данных из зашумленных данных. В обратном проходе, модель обучается предсказывать исходные данные \(x_{t-1}\), используя зашумленные данные \(x_t\) и шум \(\beta_t\).
Здесь \(\varepsilon_t\) - это шум, который модель предсказывает. В процессе обучения модель учится предсказывать этот шум.